京东到家作为即时零售领域的领先平台,其库存系统在确保商品实时可用性、支持快速履约方面扮演着关键角色。库存系统的架构设计依赖于一系列基础软件服务,这些服务共同保障系统的高可用性、可扩展性和数据一致性。本文将详述京东到家库存系统的基础软件服务架构,涵盖核心组件及其职责。
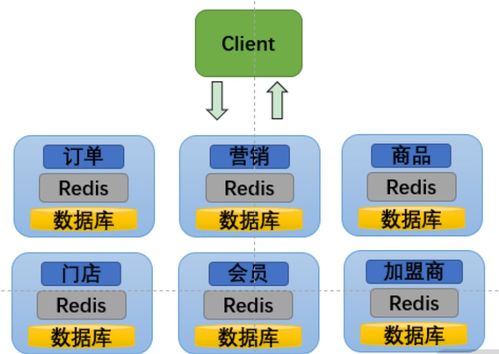
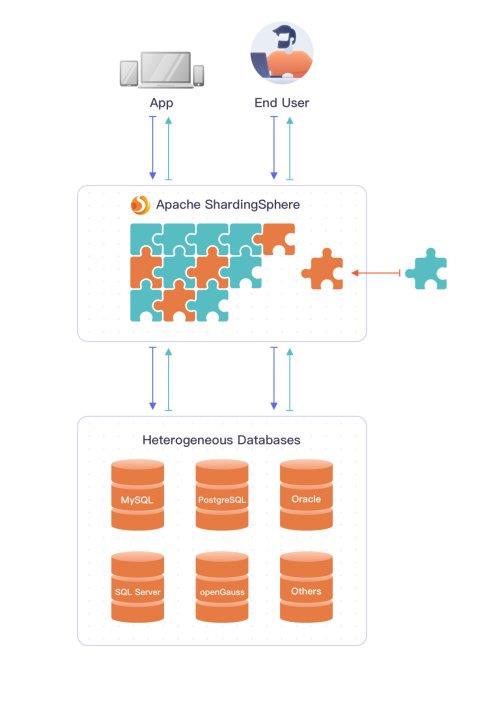
库存系统的核心是数据库层,采用分布式数据库(如TiDB或MySQL集群)来存储商品库存数据。该层负责处理高并发读写请求,并通过分片技术和主从复制机制实现水平扩展和数据冗余。为了优化性能,系统引入了缓存服务,使用Redis集群存储热点库存数据,减少数据库的直接访问压力,同时通过设置合理的过期策略和内存管理来保证数据一致性。
微服务架构是系统的基础框架,将库存管理拆分为多个独立的服务,如库存查询服务、库存更新服务和库存同步服务。每个服务通过API网关进行统一访问控制,并使用服务注册与发现组件(如Nacos或Consul)来管理服务实例的动态注册和负载均衡。这有助于提升系统的可维护性和弹性,当某个服务出现故障时,可以快速隔离和恢复。
消息队列服务(如Kafka或RocketMQ)在系统中起到异步解耦的作用,处理库存变更事件。例如,当用户下单时,库存更新服务会发布消息到队列,再由其他服务(如订单处理或日志服务)消费这些消息,确保数据最终一致性并降低系统耦合度。
系统还包括监控与告警服务,集成Prometheus和Grafana来实时追踪库存系统的性能指标,如请求延迟、错误率和资源使用情况。通过设置自动化告警规则,运维团队能够及时响应潜在问题,保证服务的高可用性。
安全与权限管理服务通过OAuth 2.0或JWT令牌实现API访问控制,确保只有授权服务可以操作库存数据。数据备份与恢复机制定期将关键数据备份到对象存储(如京东云OSS),以防数据丢失。
京东到家库存系统的基础软件服务架构通过数据库、缓存、微服务、消息队列、监控和安全组件的协同工作,构建了一个高效、可靠的库存管理平台。这种设计不仅支持了平台的快速增长,还为未来扩展提供了灵活的基础。